
This article is not a technical deep dive. It’s rather a quick glimpse over what tools are available and what they can accomplish.
Having a clear idea of all the solutions in the market will definitely help in shaping our decisions when facing a problem.
The complexity of Hadoop ecosystem comes from having many tools that can be used, and not from using Hadoop itself.
So, explaining the core ecosystem, categorizing these tools, highlighting on the major trade-offs, will make it a lot easier to understand and anticipate.
Hadoop
Apache Hadoop is an open source software platform for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware — Apache Hortonworks
To break it down. It has three main points:
1. A software platform. It runs on cluster of nodes (servers).
2. A distributed storage. It’s a filesystem that stores files across multiple hard drives. Though, we can visualize all of them as a single file system. It keeps copies of the data and recover automatically.
3. A distributed processing. All processing (like aggregation of data) is distributed across all nodes in parallel.
Hadoop was developed at Yahoo! to support distribution for the “Nutch”; a search engine project. While the data storage is inspired by Google File System (GFS), and data processing is inspired by MapReduce.
— What Hadoop is used for?
It’s for batch processing, but some solutions built on top of Hadoop provide interactive querying (CRUD applications), and we’ll go through them.
Batch processing means processing of batch of separate jobs (tasks) at the background given the fact it wasn’t triggered by the user (no user interaction), such as calculating user monthly bill.
The scaling and distribution of storage and work is horizontal.
With vertical scaling, still, we’ll face issues like: disk seek times (one big disk vs many smaller disks), handle hardware failures (one machine vs data copied among different machines), processing times (one machine vs in parallel).
Core Hadoop
What’s part of Hadoop itself?
HDFS, YARN, and MapReduce. These solutions are built on top of Hadoop directly. Everything else is integrated with it.
HDFS
It’s a file system. The data storage of Hadoop. Just like Amazon S3 and Google Storage.
HDFS can handle large files that are broken and distributed across machines in the cluster. It does this by breaking the files into blocks. And so, no more huge number of small files.
We can access the distributed data in parallel (say, for processing). It stores a copies of a block on different machines. So, machines talk to each other for replication.
Diving a little in its architecture.
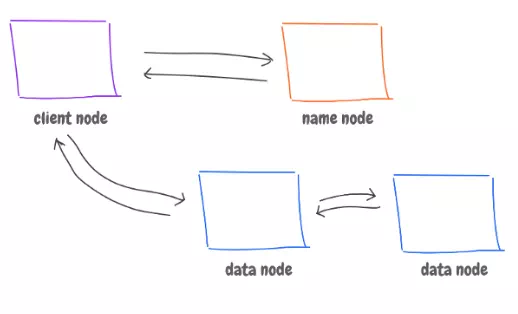
First. A name node that tracks of where each block lives, and data nodes that have the blocks.
When reading …
1. Our application uses a client library that talks to name node, and it asks for a specific data (file).
2. The name node replies back with the data node(s) that have the data.
3. The client library talks to these data nodes, and sends the result back to us.
When writing …
1. The client library will inform the name node about the writing operation.
2. The name node will reply back by where to store this file, and new entry for that file has been created.
3. The client library go and save the file data in the given location (node X).
4. The node X then talks to other machines for replication. And send back to the client library acknowledging the data has been stored and replicated.
5. The client library forwards that acknowledgment to the name node that data has been stored, and where it was replicated.
6. The name node updates its tracking metadata.
The name node is obviously a single point of failure. However, It’s important to have a single node as they may not agree on where data should be stored. To solve the problem, a backup name node can take over when the main node fails.
YARN
YARN: Yet, another resource negotiator. The resource (CPU, memory, disk, network) management layer of Hadoop.
It splits the work — in this case resource management and job scheduling and monitoring, across the nodes, taking care data ‘processing’.
It was part of Hadoop, but then split out, allowed data processing tools like graph processing, interactive processing, stream processing, and batch processing to run and process the stored data. We’ll see examples next.
An abstract view of its architecture.
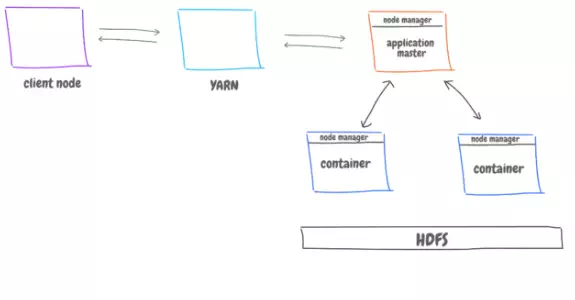
1. The client talks to YARN, and YARN then spin up a node running application master.
2. YARN allocates resources to the applications running, and passes the jobs coming to the master to be executed.
3. The application master talk to other (worker) nodes, which are running containers that execute the job, and talk to HDFS to get the data to be processed and save the result back.
4. The application master can also ask for more resources from YARN, track their status and monitor the progress.
5. Each node has its own node manager, which tracks what each node is doing, and constantly report back to YARN with the node status.
