
A distributed NoSQL database with no point of failure (no master node). It has a query language CQL, similar to SQL, but limited to what you can do.
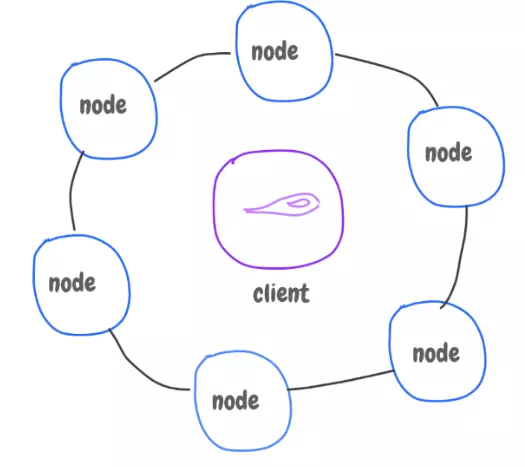
The architecture has a ring of nodes connected to each other, no master node. They communicate to replicate data, and know who has what data.
A keyspace is like a database in relational database. It has denormalized tables (no joins), partitioned based on the primary key.
The client application talks to a node asking for a data, given its key. The node replies back with where to find the data, since they can talk to each other, and find out where this data is stored, and replicated.
Cassandra has good integration with other tools like Spark. So, we can:
1. Read data stored in Cassandra for analytics.
2. Write the result data back to Cassandra.
With Spark, we can read and write tables as DataFrames.
We can even setup another replica ring, used to be integrated with Hadoop, and run Spark, Pig, for analytics, while the main ring is for web interactions; CRUD operations.
MongoDB
It’s a document based model (has JSON format). MongoDB has a single master. It’s a schema-less, each document has a unique Id, and we can have indexes around keys for fast lookups.
It’s architecture is based on M-S. Writes to master, and replicated to slaves. When master goes down, one of the salves takes over. Replica are for availability, and not to scale.
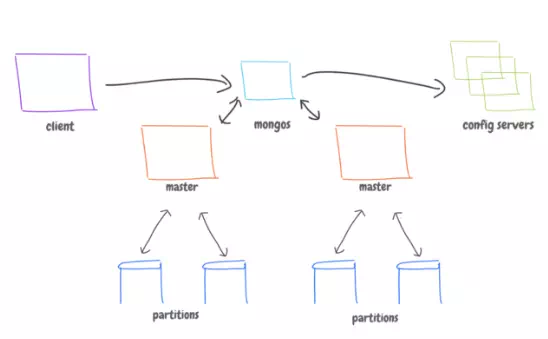
The sharding is done based on unique key of document. Data is split among M-S architectures. Each M-S handles data in a range, say 1–100, 101–200, etc. MongoDB does rebalancing automatically to ensure data is distributed evenly.
The application code talks to “mongos” (library), which talks to master servers, and config servers.
There are some quirks with MongoDB.
· We need odd number of servers to agree on primary (master) server.
· Application code is tied to servers and needs to know about them.
· Auto balancing may fail.
· We must have 3 config servers. If one is down, so the whole database.
And some interesting facts about MongoDB …
· It has built-in aggregation, map/reduce code, and file system (like HDFS).
· It can integrate with Hadoop, Spark, and most languages. So, Spark may forward the map/reduce code to MongoDB; no need to use MapReduce.
Choosing your database
While there might not be a bullet proof, straight-forward solution. There are some points to consider when making a decision.
The most important point to highlight on is explained by the CAP Theorem.
· Consistency. Data is consistent among databases (partitions & replica). Its OK to experience some latency. The consistency does matter.
· Availability. Data is always available. Always get result even If its not consistent yet (out of sync). And consistency will be checked (sync) later (at background). This is called “eventually consistent”.
· Partition-tolerance: Data can be partitioned.
For example, Cassandra prefers availability over consistency. Though, It can also force consistency by asking a number of nodes to confirm on the same answer when reading.
HBase (and MongoDB) prefer consistency. It has a master node, and thats a single point of failure; though, can have replica.
MySQL. It’s hard to partition but provides good availability and consistency.
Another aspect is, what are the components you need, and how well they are integrated. And, Do you really need Hadoop in the first place?.
— Using Hadoop + Spark Vs External databases
· Hadoop. If you want to run analytical jobs at the background, and won’t be exposed to users.
· External: If you want to run queries on real time, and expose it to users.
· Both: For analytical data to be computed by Hadoop (at background) and push it to database occasionally.
