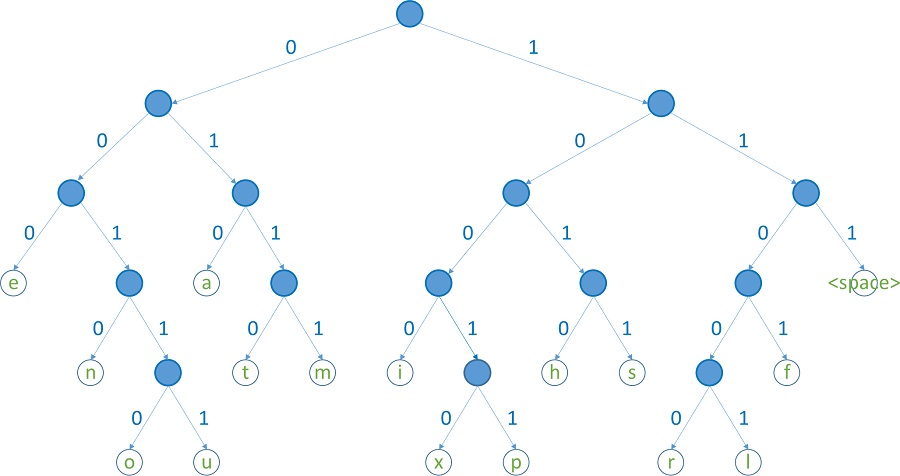
Huffman coding is an entropy encoding algorithm used for lossless datacompression. The term refers to the use of a variable-length code table for encoding a source symbol (such as a character in a file)
Huffman coding uses a specific method for choosing the representation for each symbol, resulting in a prefix code (sometimes called “prefix-free codes”) (that is, the bit string representing some particular symbol is never a prefix of the bit string representing any other symbol) that expresses the most common characters using shorter strings of bits than are used for less common source symbols. Huffman was able to design the most efficient compression method of this type: no other mapping of individual source symbols to unique strings of bits will produce a smaller average output size when the actual symbol frequencies agree with those used to create the code.
Although Huffman coding is optimal for a symbol-by-symbol coding (i.e. a stream of unrelated symbols) with a known input probability distribution, its optimality can sometimes accidentally be over-stated. For example, arithmetic coding and LZW coding often have better compression capability.
Given
A set of symbols and their weights (usually proportional to probabilities).
Find
A prefix-free binary code (a set of codewords) with minimum expected codeword length (equivalently, a tree with minimum weighted path length).
Input.
Alphabet , which is the symbol alphabet of size n.
Set , which is the set of the (positive) symbol weights (usually proportional to probabilities), i.e. .
Output.
Code , which is the set of (binary) codewords, where ci is the codeword for .
Goal.
Let be the weighted path length of code C. Condition: for any code .
For any code that is biunique, meaning that the code is uniquely decodable, the sum of the probability budgets across all symbols is always less than or equal to one. In this example, the sum is strictly equal to one; as a result, the code is termed a complete code. If this is not the case, you can always derive an equivalent code by adding extra symbols (with associated null probabilities), to make the code complete while keeping it biunique. In general, a Huffman code need not be unique, but it is always one of the codes minimizing L(C).
