Introduction 🌍💾
In today’s digital world, massive amounts of data—often referred to as Big Data—are generated every second. Businesses, governments, and researchers need efficient ways to store, process, and analyze this data. This is where Hadoop comes in!
Apache Hadoop is an open-source framework that allows for the distributed storage and processing of large datasets across multiple computers. It enables organizations to handle petabytes of data efficiently, making it a critical tool for industries like finance, healthcare, e-commerce, and social media.
But what exactly is Hadoop, and how does it help in Big Data processing? Let’s dive into the details!
What Is Hadoop? 🏗️🔍
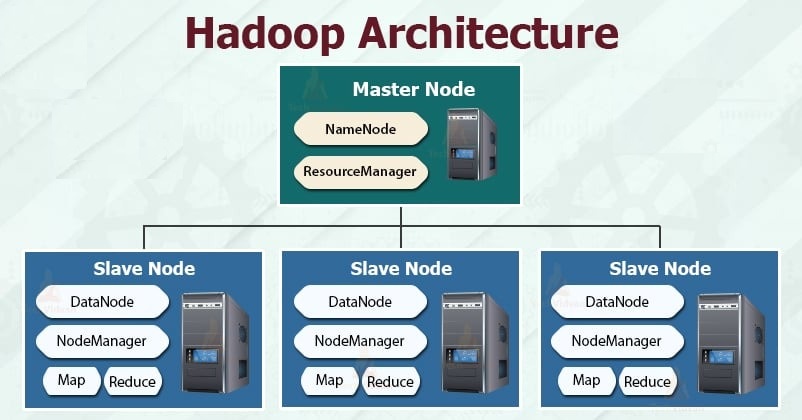
Apache Hadoop is a framework that allows for the distributed processing of large datasets across a network of computers. It follows a master-slave architecture and provides fault tolerance, scalability, and efficiency.
Key Components of Hadoop 🏗️⚙️
Hadoop consists of four main components that work together:
1. Hadoop Distributed File System (HDFS) 🗄️
HDFS is a scalable and fault-tolerant storage system designed to handle large files. It splits data into blocks and distributes them across multiple nodes (computers).
✔️ Stores large files across multiple machines
✔️ Replicates data to prevent loss
✔️ Handles structured, semi-structured, and unstructured data
🔍 Example: If a 1TB file is stored in HDFS, it is split into smaller chunks (blocks) and distributed across different servers.
2. YARN (Yet Another Resource Negotiator) 🎛️
YARN is responsible for resource management and job scheduling. It ensures that different tasks in a Hadoop cluster get the necessary computing power.
✔️ Allocates CPU and memory resources
✔️ Manages multiple applications running simultaneously
✔️ Improves cluster efficiency
🔍 Example: YARN ensures that a large-scale data processing task is efficiently executed by distributing workloads across multiple nodes.
3. MapReduce 🗺️➡️✂️
MapReduce is Hadoop’s processing engine that divides a large data task into smaller sub-tasks and processes them in parallel across multiple machines.
✔️ Processes data in parallel for speed and efficiency
✔️ Handles massive datasets efficiently
✔️ Uses “Map” (splitting) and “Reduce” (aggregating) steps
🔍 Example: If you want to count the number of words in a large dataset, MapReduce splits the data, counts words in chunks (“Map”), and then combines the results (“Reduce”).
4. Hadoop Common 🔗
This is a collection of libraries and utilities used by other Hadoop components. It allows different modules to communicate with each other.
✔️ Provides necessary Java libraries
✔️ Ensures compatibility between Hadoop components
How Does Hadoop Help in Big Data Processing? 📊⚡
Hadoop is a game-changer for Big Data analytics. Here’s how it helps:
1. Distributed Storage & Processing 🖥️💾
Hadoop stores and processes data across multiple nodes (computers), reducing processing time significantly. Instead of relying on a single server, it distributes tasks for faster execution.
🔍 Example: If a bank wants to analyze customer transactions from millions of users, Hadoop can split the data and process it simultaneously, making analysis much faster.
2. Scalability 📈
Hadoop clusters can grow as data volume increases. You can easily add more machines (nodes) to expand storage and processing power.
🔍 Example: E-commerce giants like Amazon and Alibaba use Hadoop to scale their data processing as customer demand grows.
3. Fault Tolerance 🔄
If one machine fails, Hadoop automatically shifts the workload to other available nodes, ensuring uninterrupted data processing.
🔍 Example: If a node storing a customer’s purchase history fails, Hadoop retrieves the data from its replicated copy on another node.
4. Cost-Effective 💰
Since Hadoop runs on commodity hardware (low-cost computers), it is much cheaper than using high-end servers.
🔍 Example: Traditional data warehouses require expensive SQL databases, while Hadoop allows businesses to analyze massive datasets at a lower cost.
5. Handles Various Data Formats 📑🖼️🎙️
Hadoop can process structured, semi-structured, and unstructured data, including:
✔️ Text files (Logs, CSVs)
✔️ Images and Videos (Medical scans, security footage)
✔️ Audio files (Speech recognition, customer service calls)
🔍 Example: Netflix uses Hadoop to analyze user viewing habits from video streams, helping recommend personalized content.
Real-World Applications of Hadoop 🌍🚀
Hadoop is used across industries for data analysis, machine learning, and real-time processing.
1. Social Media & Online Platforms 📱💬
🔹 Facebook & Twitter use Hadoop to process billions of user interactions (likes, shares, tweets).
🔹 YouTube analyzes video engagement trends using Hadoop.
2. Finance & Banking 🏦💰
🔹 Banks use Hadoop for fraud detection by analyzing millions of transactions in real time.
🔹 Stock markets use it to predict market trends.
3. Healthcare & Genomics 🏥🧬
🔹 Hospitals analyze patient data for early disease detection.
🔹 Genomics researchers use Hadoop for DNA sequencing.
4. E-commerce & Retail 🛒🛍️
🔹 Amazon & eBay use Hadoop to track customer buying patterns.
🔹 Walmart processes millions of sales records daily to optimize inventory.
5. Cybersecurity & Fraud Detection 🔐🚨
🔹 Government agencies analyze large datasets to track suspicious online activities.
🔹 Financial institutions use Hadoop to detect fraudulent transactions.
Challenges of Hadoop 🏗️⚠️
Despite its advantages, Hadoop has some limitations:
🔹 Complexity – Requires expertise in Java, Python, or Scala.
🔹 Latency Issues – Not ideal for real-time processing (alternatives like Apache Spark are faster).
🔹 Security Concerns – Hadoop lacks built-in encryption, making security a challenge.
🔹 Hardware Requirements – Needs multiple nodes, which may be costly for small businesses.
Future of Hadoop & Big Data 🚀🔮
As Big Data grows, Hadoop is evolving with new technologies:
🌍 Integration with Cloud Computing – Services like AWS, Google Cloud, and Microsoft Azure offer Hadoop-based solutions.
⚡ Apache Spark & Real-Time Processing – Spark is faster than Hadoop and is often used alongside it.
🤖 AI & Machine Learning Integration – Hadoop is being combined with AI to enhance data analysis.
Conclusion 🏆📊
Hadoop is a powerful tool for handling massive amounts of data across industries. Its ability to store, process, and analyze data at scale makes it an essential technology in the Big Data revolution.
While Hadoop has challenges, its cost-effectiveness, scalability, and efficiency make it an invaluable asset for companies dealing with large datasets. As technology evolves, Hadoop will continue to play a vital role in data analytics, AI, and cloud computing.