
That’s where clearly separating training and prediction comes in handy. If we saved our feature engineering methods and our model parameters, then we can build a simple REST API with these elements.
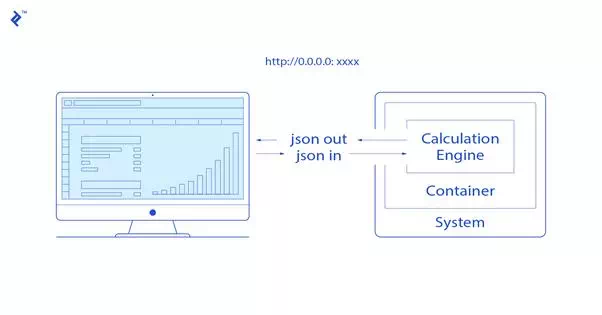
The key here is to load the model and parameters at the API launch. Once launched and stored in memory, each API call triggers the feature engineering calculation and the “predict” method of the ML algorithm. Both are usually fast enough to ensure a real-time response.
The API can be designed to accept a unique example to be predicted, or several different ones (batch predictions).
Here is the minimal Python/Flask code that implements this principle, with JSON in and JSON out (question in, answer out):
app = Flask(__name__) @app.route('/api/makecalc/', methods=['POST']) def makecalc(): """ Function run at each API call No need to re-load the model """ # reads the received json jsonfile = request.get_json() res = dict() for key in jsonfile.keys(): # calculates and predicts res[key] = model.predict(doTheCalculation(key)) # returns a json file return jsonify(res) if __name__ == '__main__': # Model is loaded when the API is launched model = pickle.load(open('modelfile', 'rb')) app.run(debug=True) Note that the API can be used for predicting from new data, but I don’t recommend using it for training the model. It could be used, but this complexifies model training code and could be more demanding in terms of memory resources.

Comments are closed