
It runs on top of YARN. It’s an alternative to MapReduce. In fact, we can configure some of the tools that run on MapReduce by default like Hive and Pig to run on Tez instead.
— So, What’s good about it?
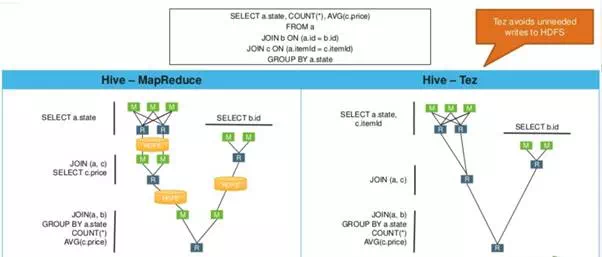
Tez tries to analyze the relationship between the steps & independent paths, and figure out the most optimal path for executing the queries.
It tries to run the steps in parallel instead of in sequence as in MapReduce, as It has a complete view or awareness of the job, before running it. It also optimize the resource usage, and minimize the move of data around.
This is called “Directed Acyclic Graph (DAG)”. It about accelerating the jobs.
Spark
It can set on top of YARN, and an alternative to MapReduce, allowing to use programming language like Python, Java or Scala to write queries. It uses the idea of map/reduce, but not the exact implementation.
Besides, It provides many functionalities for ML, data mining, streaming. And, uses DAG, same as in Tez.
— How It works?
It’s based on RDD; An object represents the dataset thats actually being distributed across nodes in the cluster and has a set of built-in methods.
So, we, just deal with a dataset; a single object, though, it’s distributed.
Here is an example in code to demonstrate. The problem is to get the count of how many each movie was rated.
# Create the Spark context object
sc = SparkContext(conf = conf)
# 1. Load the data from a source like HDFS. It returns an RDD.
lines = sc.textFile("hdfs:///user/.../movies.data")
# 2. Map. Transform each line to: (movieId, 1) using mapper function
movieRatings = lines.map(mapper)
# 3. Reduce. Given each movieId = [1,1, ...], count the ratings.
# The value array for each movie is passed as accumulated & current value. Why? To break an array in pieces, and apply a function in parallel. Want to visualize how it works?.movieCount = movieRatings.reduceByKey(lambda acc, curr: acc + curr)
# We can also apply functions like sort
sortedMovies = movieCount.sortBy(lambda m: m[1])
Spark won’t kick-off unless we call one of the “action” functions (reduce, collect, etc). So, It determines the fastest way to perform the action and get the result.
DataFrames
With Spark 2.0 DataFrames was introduced. DataFrames extends RDD. It contains row objects, each has name and datatype (instead of just tuple), and we can run SQL queries. An example for the same scenario above.
# mapper returns a Row object: (movieId=INT, rating=1)
movieRatings = lines.map(mapper)
# Convert the RDD to a DataFrame
movieDataset = spark.createDataFrame(movieRatings)
# Group by movieId and get the count of ratings
movieCount = movieDataset.groupBy("movieId").count("rating")
# Order by ratings
sortedMovies = movieCount.orderBy("rating")
As you noticed, we can perform the same task with less and easier code. It’s more efficient since the data has structure. DataFrames can also be used with ML and streaming capabilities built on top of Spark.
A common example is to predict the movie recommendations of a user.
# mapper returns a Row object: (userId=INT, movieId=INT, rating=FLOAT)
userRatings = lines.map(mapper)
# Convert the RDD to a DataFrame
userDataset = spark.createDataFrame(userRatings)
# Train the model (ALS)
als = ALS(maxIter=5, regParam=0.01, userCol="userId", itemCol="movieId", ratingCol="rating")
model = als.fit(userDataset)
# Predict movie recommendations given a list of movies of a userId
recommendations = model.transform(movies)
Pig
It runs on top of MapReduce and provides an interface to write SQL-like script, a procedural language called ‘Pig’, instead of Java or Python.
It lets us do what we can do with MapReduce (write map/reduce jobs) in a simpler way. We can define user custom functions. And, we can still run mappers and reducers. Also, It can run on its own without Hadoop.
Using the example above of the movie count. A Pig script looks like:
# Load the data from HDFS. A schema is applied on data load.
# The ratings is an array (series) of tuples
ratings = LOAD '/user/.../movies.data' AS (movieId:int, rating:int);
# Group by movieId. Returns an array of tuples. The first value is
# the movieId, and second called 'bag': matching rows.
# Under the hood, Pig is using mapper and reducer to get the result.
ratingsByMovie = GROUP ratings BY movieId
# Count ratings of each movie
# ratings gives access to the bag of each group (movieId)
movieCount = FOREACH ratingsByMovie GENERATE group AS movieId, COUNT(ratings.rating) AS countRating;
# Order by ratings
sortedMovies = ORDER movieCount BY countRating DESC;
There is a lot more on Pig. Other commands, connect to different data sources, user-defined functions.
Hive
It solves almost same problem as Pig. It takes a SQL queries (HiveSQL), as if the data is stored in a relation database (in fact, it’s not).
Hive will then execute SQL on multiple nodes and process it in parallel, and return the final result. It translates the SQL queries to mapper and reducers on top of MapReduce.
And same as Pig. It’s easier than to write map and reduce in code.
It’s not optimized for interactive queries. Its for analytics queries (at the background).
But with SQL, It’s limited. There is no way to chain methods like in Spark or Pig. There is no update, insert, or delete operations. In fact, there is no physical table at all (only logical). Under the hood, the data is denormalized.
Here is how It works …
It creates a schema that gets applied on data when it’s being read. In traditional relational database, schema is applied when data is loaded.
So, it’s taking unstructured data, and applying a schema on read. It doesn’t copy the data. Loading the data will move data to Hive directory (which still in HDFS). It doesn’t reformat the data.
It then creates “views”; a logical table as result of a query. Now this data is owned by Hive. If we drop a table in Hive, the data is gone!.
But, still, can have external tables, which share existing data given its location in HDFS. So, data is not in Hive directory, and Hive will just drop the schema.
CREATE VIEW IF NOT EXISTS movieCount AS
SELECT movieId, COUNT(rating) AS countRating
FROM movieRatings
GROUP BY movieId
ORDER BY countRating DESC;
SELECT * FROM movieCount LIMIT 10;
