
We can use and integrate external data storage, relational and non-relational databases to expose the data to transactional platform (like interactive web applications).
We can import & export data directly to & from HDFS, and the data might be transformed by Spark or MapReduce.
MySQL
MySQL, is a monolithic, not distributed, relational database. It’s good for interactive queries (web based apps).
With MySQL, we can import and export data using Sqoop. Sqoop kicks off bunch of mappers, and populate the data to HDFS (or MySQL).
· We can import or export with the option to use Hive directly.
· We can also give number of mappers to run.
· We can have incremental imports based on last value of a column (timestamp). So to keep data in HDFS in sync.
If all what you need is to answer queries very fast using a key (data is denormalized). Then, a NoSQL database might be a good candidate. NoSQL is better when you favor the speed and scaling over consistency.
HBase
A NoSQL database sets on top of HDFS. It’s an implementation of Google Big Table.
There is no query language. And only CRUD via API. It partitions the data automatically, and re-partition, and auto scale as the data grows.
A quick peek at the overall architecture and data model.
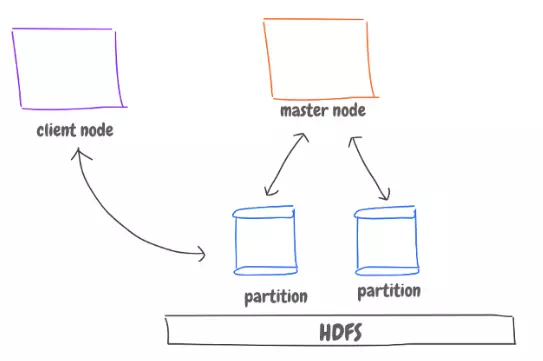
The master nodes know where the data is stored and how partitioned, but it’s not meant to be queried. We talk to partitioned servers (salves) directly. Each partition has data of key range of, say 1–100, 101–200, etc.
· It consists of a collection of tables. Each table has rows, each identified by rowkey, and keys are stored in lexicographical order.
· Each row consists of family columns (a set of related columns).
· Each cell may have different versions with timestamps.
It’s schema-less. It can store sparse data; not all rows have to have the same columns. If data doesn’t exist at a column, it’s not stored. This also allows us to dynamically add columns.
CustomerName: { // column family in a row
‘FN’:1383859182496:‘John’, // column name, version, value
‘LN’:1383859182858:‘Smith’}
ContactInfo: { // another column family in the same row
‘EA’:1383859183030:‘john.smith@domain.com’,
’SA’:1383859183073:’5th Avenue’}
The format of data does matter, and it’s depends on how we query the data. So, If you’ll query the movies given a user, then structure should be look like
# userId is the key, and movies is a column family
userId,
movies: {
movieId1: rating,
movieId2: rating,
...
}

