
With Spark core, we can analyze batch of data (say, daily). With Spark Streaming, we analyze data in real time as it comes in.
A high-level overview of how it works.
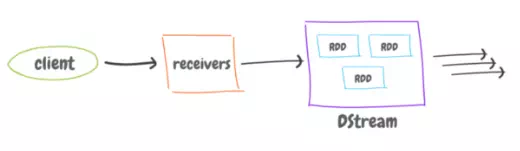
1. As the data comes in from the source to the ‘receivers’, a batch (chunk) of this data is created for every interval of time.
2. The DStream create RDD for each batch interval. We can transform or play around with the RDD before sending to other systems. So, we are just writing Spark code. A function can be applied on every batch.
3. Batches are then sent to other systems, whoever is listening.
Now, we might need to apply a function over a longer period of time, instead on every batch. This is called ‘Windowing’.
For example, having a batch with interval is 1 second, but maintain the result of batches within 1 hour. And the window slides (1 hour interval) forwards as the times goes on. We can set this function to be applied every say, 10 min, on every last 1 hour interval.
An example could be, take the logs as it comes in, count top requested URLs over every window interval, and save it to the database.
— DataFrames
And as Spark core is moving towards DataFrames, and so Spark Streaming.
Data coming is stored in DataFrames, instead of dealing with individual RDDs in DStream. It’s like a table of rows, and so has structure, where rows are getting appended to it.
It’s easy to code; since code of non-streaming data wouldn’t be much different for streaming data. And has a better performance for SQL-like queries, and better integration with ML Spark API.
Storm
Apache Storm. Another solution to process and analyze real time data as it comes in. It’s built on its own, but can run on top of YARN.
It works on events (each sample of data is an event; real-time) not batches of data as in Spark Streaming.
The way It works might sound now familiar. It has:
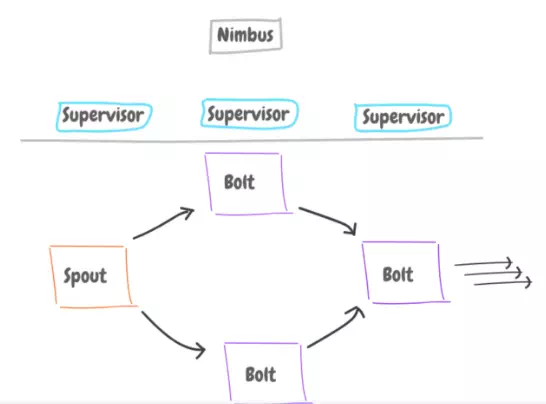
· Spouts: The source of data, can be an application, Kafka, etc.
· Tuples: The stream consists of tuples, each is a single data.
· Bolts: Receive, transform, aggregate, and send data to database, or file, as the data comes in.
· Nimbus: Track of jobs and whats happening (has a backup for recovery).
· Supervisor: Worker nodes, where all the processing takes place.
We can have a topology, with different Spouts and Bolts connected to each other. For example, a Spouts that passes logs data to two bolts, one after another, one to format the logs, and another to count similar URLs.
—
Spark has Storm Vs Spark Streaming more advantages like ML, and easy to write Spark code with many languages. While Storm application usually written in Java, but It’s more real-time as it deals with events not batches.
Flink
It similar to, yet might be faster than, Storm, and the newest of them.
Flink has real time streaming on events (real-time), and also batch streaming. It uses snapshots; can survive failures and ensures an event will be processed once in the correct order.
Flink supports Scala, has its own libraries for things like ML (same as Spark), and has a UI showing the running work.
On top of the Flink runtime engine:
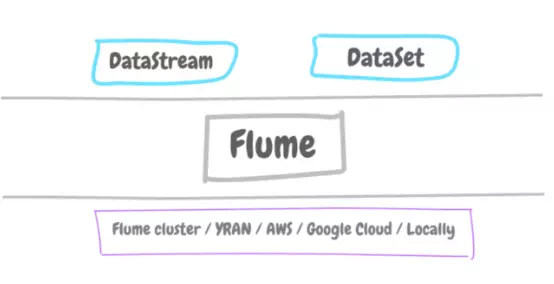
· DataStream API for real-time data. DataStream API supports libraries for SQL queries (as data comes in).
· DataSet API for batch data. DataSet API supports libraries for ML, graphics, SQL queries. Same as Spark.
At the bottom. It can run on top of its own cluster, YARN (Hadoop), or AWS, or Google Cloud, or event locally.

