
So far we assumed data is sitting on the cluster, but, we didn’t say how to get the data as it comes in into the cluster for analysis.
For sure we can have a database, but, we can also format and analyze the data as it comes in.
Streaming is when the data being sent from the source to be processed. For example, log entries, sensor data, stock data, etc.
There are two problems here:
1. How can we get data from different sources. Kafka, Flume.
2. How to process it when it gets there. Spark Streaming, Storm, Flink.
Kafka
A general-purpose publish / subscribe messaging system. It’s not just for Hadoop.
It gets incoming messages (data) from publishers (sources), and publish them to a stream of data called ‘topic’ (like logs). Then, subscribers can listen to these topics and get data as it’s being published.
Kafka stores the incoming data for a while, just in case any subscriber failed to pick up.When the subscriber starts again, it will start from where it left off.
The architecture has a box at the center, that’s the Kafka cluster. It has processes and data, all distributed across servers.
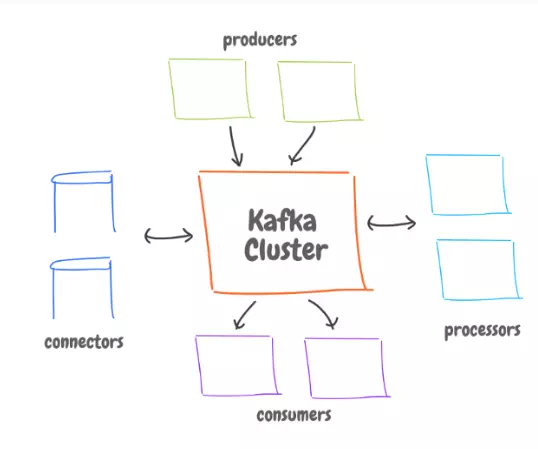
To get the whole picture:
· Producers. Our applications that push data to Kafka coming from sources.
· Consumers: Any applications that receives data from Kafka. Consumers listening to the same topic can be grouped so that incoming data will be distributed among them.
· Connectors: Databases that can publish and receive data from Kafka.
· Stream Processors: To re-structure or format the incoming data, and send it back to Kafka.
Flume
It was built with Hadoop in mind unlike Kafka which is general purpose. It was originally built to aggregate the logs coming from different web servers, and send it to Hadoop.
It architecture is called ‘Agent’, and consists of:
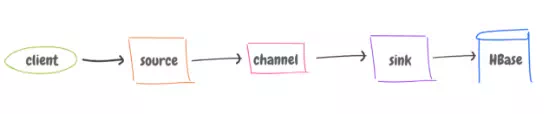
· Source: It listens to, say, a web server. It can format data or add logic to where to send the data.
· Channel: Determines how data is transferred from source to sink (via memory or file). The memory is faster, while file has persistence to recover from failures.
· Sink: Connects to the wherever the data will go. A sink can connect to only one channel. Flume has built-in sinks to write data to HDFS and HBase.
Unlike Kafka, once the sink receives the data from the channel, it gets deleted from the channel. So, it’s hard to have multiple sinks listening to the same data at different rates.


Comments are closed