
There are handful of solution to query the data in the whole cluster, or from a certain database. Hive and Pig can also be candidates, but they are also part of Hadoop Ecosystem.
Drill
With Apache Drill, we can write SQL queries (and not SQL-like, unlike Hive) that run across NoSQL databases and data file sources like HBase, Cassandra, Amazon S3, etc.
We can join data from different sources, and tight them together in one SQL query.
It’s fast, but still it’s not real relational under the hood. It saves data as JSON. Data from different sources will be translated into databases and tables.
So, one can write a query to get number of movies that were rated by each user, integrating data from Hive and MongoDB.
SELECT u.name, COUNT(*) AS moviesRated
FROM hive.movies m
JOIN mongo.users u
ON m.user_id = u.user_id
GROUP BY (u.user_id)
Phoenix
Apache Phoenix. The SQL solution for HBase. It sets on top it.
It supports transactions (ACID), secondary indexes, and user defined functions. It’s fast, low-latency, good for analytics and transactions applications. But still, we don’t with relational database.
— Why not to use HBase directly?
Because SQL can be easier. Instead, we can optimize HBase, like having a denormalized table only for answering queries.
Phoenix talks HBase API, which talks to HBase server. Each HBase server has a Phoenix co-processor attached to it.
Other tools like Hive, Pig, Spark, and MapReduce, can be integrated with it. For example, Pig can be used to access Phoenix, which in turns access HBase.
A simple SQL query using Phoenix.
SELECT * FROM users;
Presto
Presto an open-source SQL query engine, created by Facebook.
Its same as Drill. SQL-like syntax. Runs across different sources, and optimized for analytical queries. Though, facebook uses it for interactive queries on massive amount of data!.
It can connect to local files, Cassandra (unlike Drill), Hive, MySQL, Kafka, Redis, etc.
ZooKeeper
It keeps track of configurations in the cluster, shared states to ensure synchronization (like replica data), which nodes are up and down, electing master node, naming service, etc.
Many systems use it to keep track of things; whats the master server, which servers are up, and so on. It has an API, and the information is stored in a small distributed file system.
In HBase, Zookeeper watches the watcher (HBase master node). It tells which master node is running. If failed, determines which master to talk to, and ensures no two master nodes are live at a given time. A tool to let us recover from failures.
If a worker is down, It keeps a list of all tasks, so when having a new worker, we know from where to continue, and so we can re-distribute the work.
The way it works, is, it has a list of servers, or otherwise it would be a single point of failure.
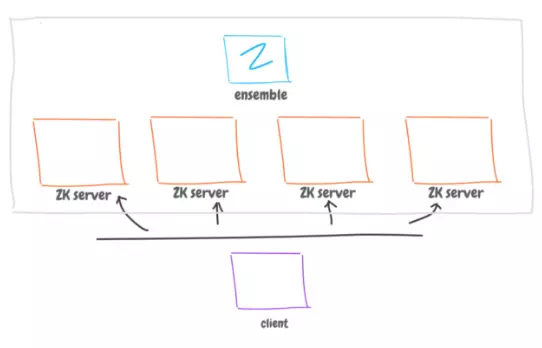
The client must know about these servers, and talk to them evenly; spread out the load. The Zookeeper ensemble will replicate data across all Zookeeper servers.
The client can specify the least number of Zookeeper servers to agree on the received information to make sure the its valid.
Oozie
Orchestrating running and scheduling Hadoop jobs. For example, If you have a task that involves jobs to run even across different tools (Hive, Spark, Hbase).
It has a workflow: Chaining a list of jobs (actions) from possibly different technologies.
A common workflow is to copy data from external data source to Hadoop, and do analytical queries on the data, then write the result back.
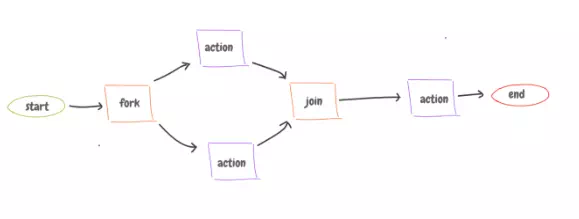
The ‘fork’ node starts parallel actions, while ‘join’ gets the result from these action, and pass it to the next action. And it uses Directed Acyclic Graph (DAG) to run jobs in parallel, if possible.
The Oozie coordinator schedules execution of the workflow periodically, define how frequently to run, and can wait for input (data) before starting.
Oozie bundle is a A collection of coordinators. For example, each coordinator process a log data and do different analysis (like understand customer behavior). It then useful so we can start and stop the entire bundle.
Zeppelin
Apache Zeppelin. A notebook interface to our data in the cluster, much like IPython Notebook.
We can interactively run scripts against the data. We can notes, and share it with other people.
It has a good integration with Spark. It can run Spark code, SQL queries, that run against SparkSQL. Results can be visualized in charts. It can be also integrated with Cassandra, Hive, HBase, etc.


Comments are closed