
This article is about using Python in the context of a machine learning or artificial intelligence (AI) system for making real-time predictions, with a Flask REST API. The architecture exposed here can be seen as a way to go from proof of concept (PoC) to minimal viable product (MVP) for machine learning applications.
Python is not the first choice one can think of when designing a real-time solution. But as Tensorflow and Scikit-Learn are some of the most used machine learning libraries supported by Python, it is used conveniently in many Jupyter Notebook PoCs.
What makes this solution doable is the fact that training takes a lot of time compared to predicting. If you think of training as the process of watching a movie and predicting the answers to questions about it, then it seems quite efficient to not have to re-watch the movie after each new question.
Training is a sort of compressed view of that “movie” and predicting is retrieving information from the compressed view. It should be really fast, whether the movie was complex or long.
Let’s implement that with a quick [Flask] example in Python!
Generic Machine Learning Architecture
Let’s start by outlining a generic training and prediction architecture flow:
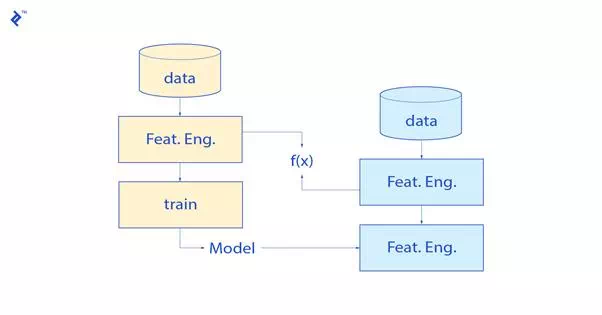
First, a training pipeline is created to learn about the past data according to an objective function.
This should output two key elements:
1. Feature engineering functions: the transformations used at training time should be reused at prediction time.
2. Model parameters: the algorithm and hyperparameters finally selected should be saved, so they can be reused at prediction time
Note that feature engineering done during training time should be carefully saved in order to be applicable to prediction. One usual problem among many others that can emerge along the way is feature scaling which is necessary for many algorithms.
If feature X1 is scaled from value 1 to 1000 and is rescaled to the [0,1] range with a function f(x) = x/max(X1), what would happen if the prediction set has a value of 2000?
Some careful adjustments should be thought of in advance so that the mapping function returns consistent outputs that will be correctly computed at prediction time.

Comments are closed